
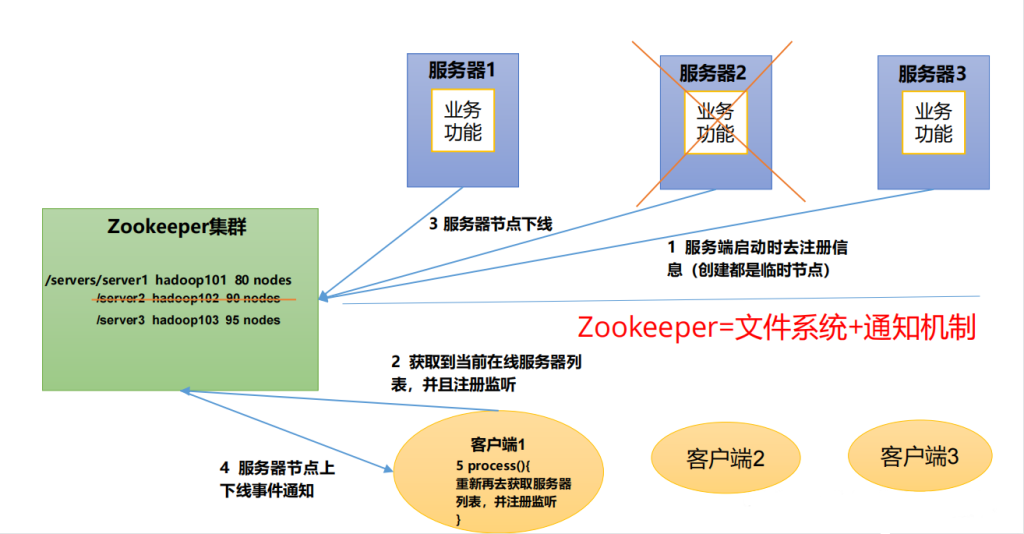
1. 脑裂
一般脑裂都是出现在集群环境中的。指的是一个集群环境中出现了多个“大脑”(类似zookeeper的master、elasticsearch的master节点)。原本是统一的一个集群对外提供服务的,现在变成了多个集群同时对外提供服务,如果断了的网络突然联通了,那么此时就会出现问题了,多个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。
出现的原因:可能就是网络环境有问题如断开,假死等等,导致一部分slave节点会重新进入崩坏恢复模式,重新选举新的master节点,然后对外提供事务服务。
![图片[1]-Zookeeper 脑裂问题-深吸氧](https://xiyang-blog.oss-cn-hangzhou.aliyuncs.com/blog/2022/10/image-38.png)
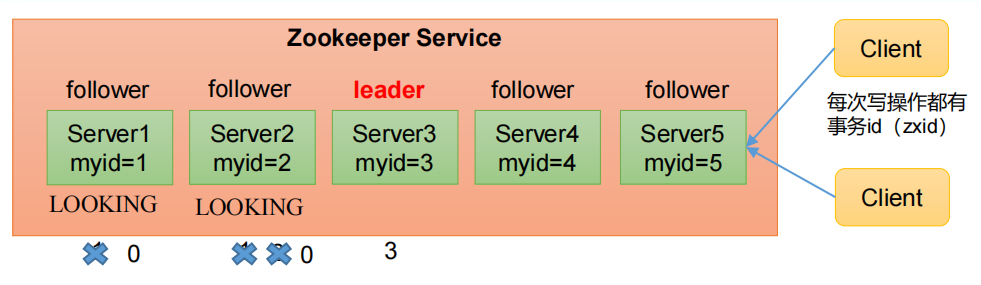
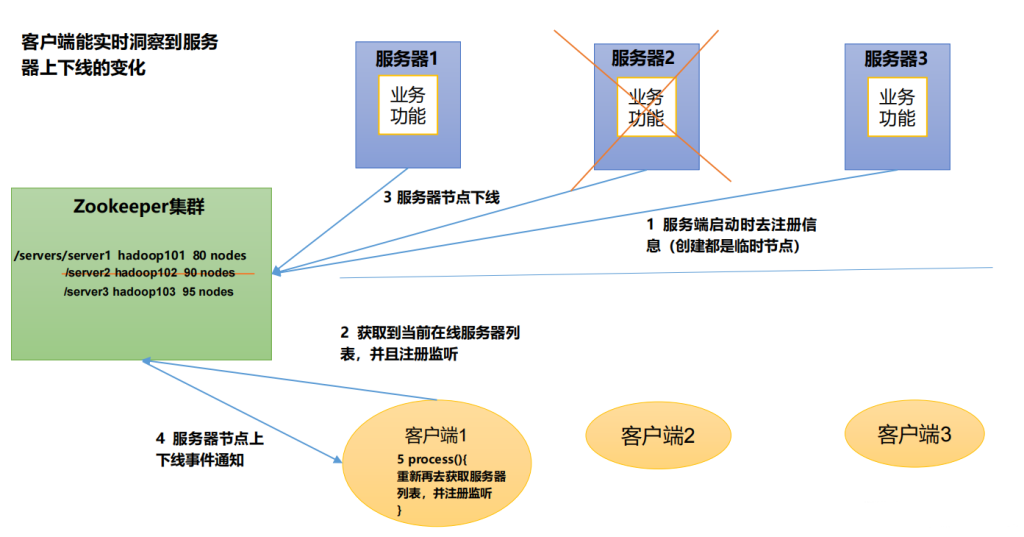
例如机房A和机房B通信,一个6个节点,选举机房A的一个节点为master节点。
当机房A和机房B出现通信网络故障,如下图会导致机房B重新选举master。在网络恢复后就会出现两个master。
![图片[2]-Zookeeper 脑裂问题-深吸氧](https://xiyang-blog.oss-cn-hangzhou.aliyuncs.com/blog/2022/10/image-40.png)
解决方法:
- 采用冗余心跳通信
- 集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
- 采用过半原则
2. 过半原则
在领导者选举的过程中,如果某台zkServer获得了
作用:
- 快速选举
- 因为这样不需要等待所有 zkServer 都投了同一个 zkServer 就可以选举出来一个Leader 了,效率比较高
- 防止脑裂
- 拿上面的图来说,n = 6,那么set.size要为4(4>3)就是在机房A和机房B中有4个节点才能选举新的master节点。如图二,机房A和B断了,机房B只有3个节点,是无法选举新的master节点的,所以就保证了即使机房A和B之间的网络断了,机房B也不会选举新的master节点,这样 zookeeper 也就能避免了脑裂问题。
3. 集群节点为奇数的原因
3.1 防止由脑裂造成的集群不可用
- 假如zookeeper集群有5个节点,发生了脑裂,脑裂成了A、B两个小集群:
- A : 1个节点 ,B :4个节点
- A : 2个节点, B :3个节点
上面这两种情况下,A、B中总会有一个小集群满足 可用节点数量 > 总节点数量/2 。所以zookeeper集群仍然能够选举出leader,仍然能对外提供服务。
- 假如zookeeper集群有4个节点,同样发生脑裂,脑裂成了A、B两个小集群:
- A : 1个节点 ,B :3个节点
- A : 2个节点, B :2个节点
情况1 是满足选举条件的。 但是情况2 就不同了,因为A和B都是2个节点,都不满足可用节点数量 > 总节点数量/2 的选举条件, 所以此时zookeeper就彻底不能提供服务了。
3.2 在容错能力相同的情况下,奇数台更节省资源
leader选举,要求 可用节点数量 > 总节点数量/2 。
- 假如zookeeper集群1 ,有3个节点,3/2=1.5 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要2个节点是正常的。换句话说,3个节点的zookeeper集群,允许有一个节点宕机。
- 假如zookeeper集群2,有4个节点,4/2=2 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要3个节点是正常的。换句话说,4个节点的zookeeper集群,也允许有一个节点宕机。
集群1与集群2都允许1个节点宕机的容错能力,但是集群2比集群1多了1个节点。多列举几个:2->0; 3->1; 4->1; 5->2; 6->2 就会发现一个规律,2n 和 2n-1 的容忍度是一样的,都是 n-1。在相同容错能力的情况下,本着节约资源的原则,zookeeper集群的节点数维持奇数个更好一些。
3.3 集群节点数量最少为3个
集群规则为:2N + 1 台,N > 0,即最少需要 3 台。两个节点,挂掉一个节点后,剩余节点无法满足过半原则,便不能提供服务。


![The server selected protocol version TLS10 is not accepted by client preferences [TLS12]-深吸氧](https://xiyang-blog.oss-cn-hangzhou.aliyuncs.com/blog/2022/02/20220224201351.png)



暂无评论内容